Auto-deploy is a really important feature of our product here at Runnable. It takes the tedium out of managing multiple testing and development environments. Via a GitHub webhook, we listen to push events that occur on our customers’ repositories and automatically deploy the changes to the Runnable Sandbox application.
A few weeks ago I ran into a situation that was rather troubling: a new branch I created didn’t show up in the app. Wondering if I had accidentally botched the command, I rechecked my terminal and confirmed that I had successfully pushed the branch to GitHub. A bit puzzled by the state of things, I decided to dig in and investigate the problem.
Starting with the webhook history in GitHub, I found that our API had responded to webhook handler with a 500 error. This was a bit odd since logic that handles webhooks is relatively straightforward and not prone to falling over. Still not fully grokking what had happened, I surfed over to our ops dashboards to see if anything was afoot during the time of the push. The graphs showed that the API was under unusually heavy load during the time. The API must have choked due to resource constraints and my push event was lost.
Noting that this was a pretty serious consistency problem, I talked the situation over with some of the other members on the team. One person said we should simply add more API instances to more evenly distribute the load. Another suggested that we take on the arduous task of factoring the webhook handling out of API completely. Yet another questioned if it was really all that important, since the existing implementation did work most of the time.
First, I considered if we should should scale-out the API, but that solution was subpar because no matter how far we scaled the system out it would eventually buckle and we’d lose push events. Next, I thought about factoring out the webhook functionality completely. Given enough time I would have loved to gone this route, but it would take quite a while and the currently implementation was working (albeit with minor hiccups). Finally, I mulled over the easiest tactic: doing nothing. This was not ideal because a single missed webhook could cause a lot of confusion for our customers.
While all fine ideas, none of the proposed solutions directly addressed the problem of losing push events. It seemed that what we needed was a thin persistence layer where the webhooks could “chillax” if the API didn’t have the resources to immediately handle them. After reviewing GitHub’s best practices article the solution became crystal clear. What we needed was a fire-and-forget worker microservice to support the API when it was overloaded.
Since we already use RabbitMQ internally the design of the new service was relatively straightforward. It would consist of exactly two parts:
An HTTP server that listened for GitHub webhook events and enqueued jobs
A worker server that dequeued jobs, deferred the logic to the API, and retried if something went wrong
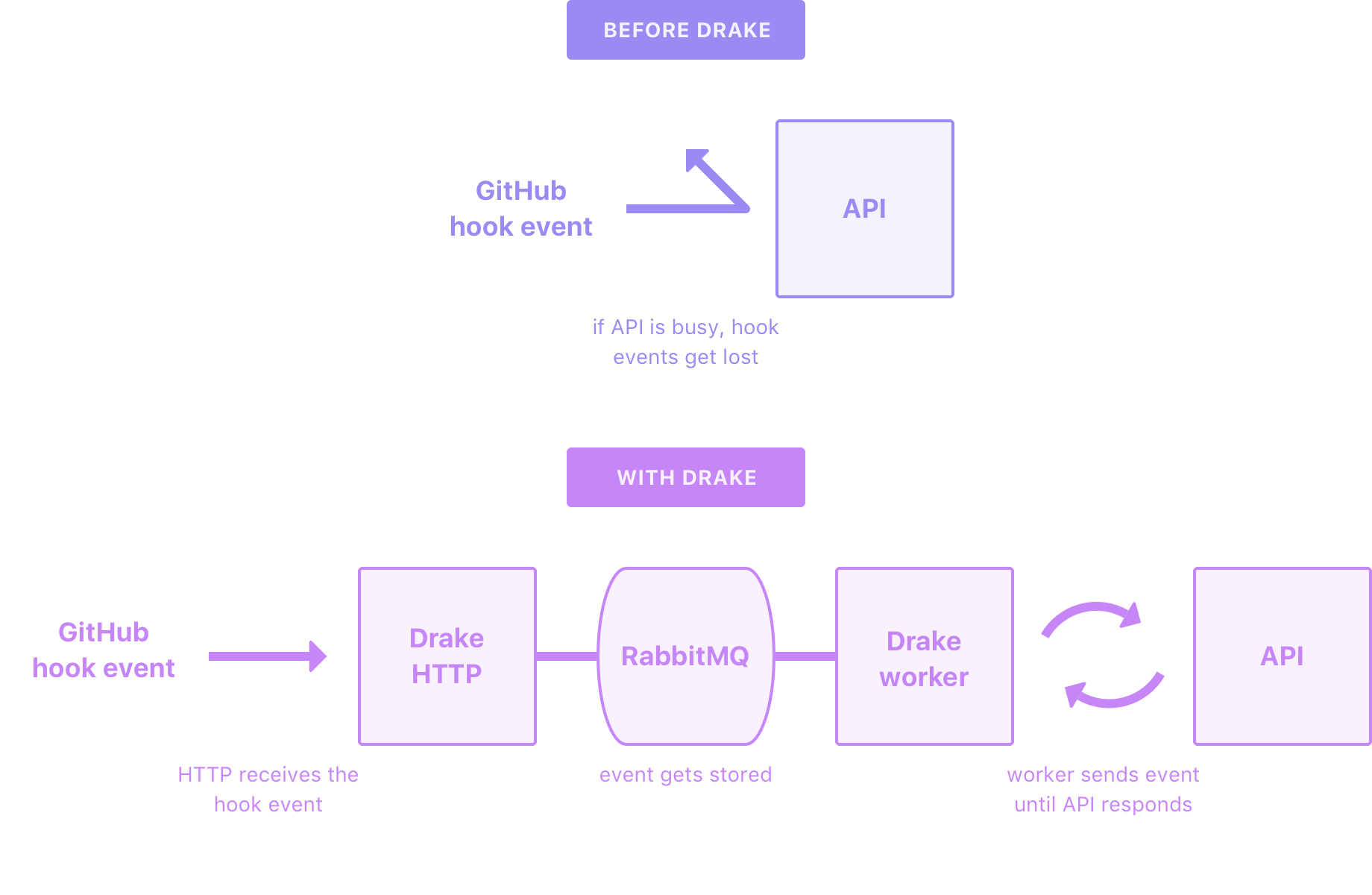
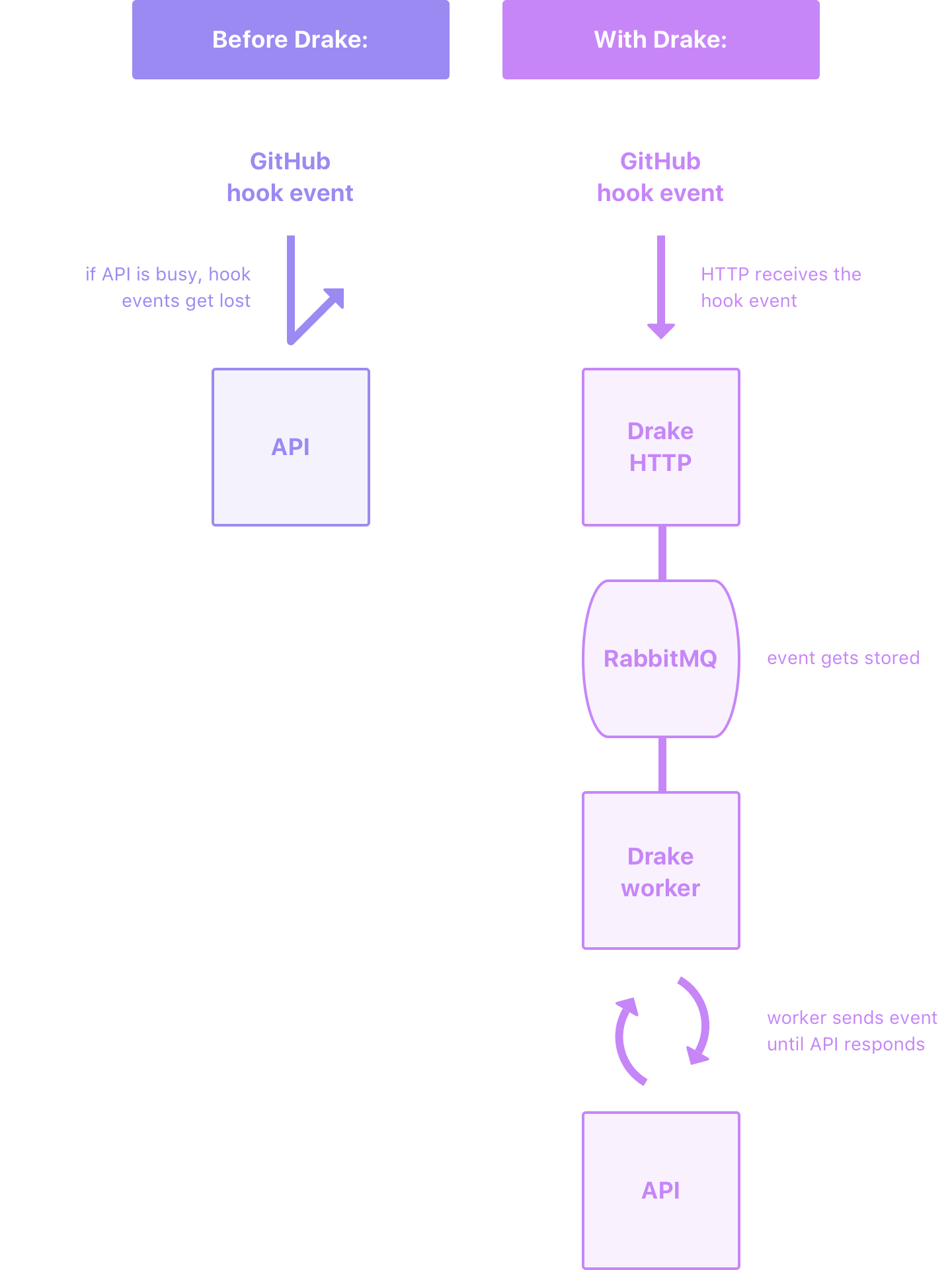
I was very pleased with the solution. First, we didn’t have to undertake a large and lengthy refactor of an existing implementation. Second, we weren’t going to be arbitrarily scaling the API to handle a simple corner-case. And finally, it gave a us a place to start if we wanted to move the logic out of the API.
But what I loved most about the solution is that it was dead simple. Start to finish the project only took four days. This included 100% test coverage, sanity checking, code review, migrating existing webhooks, and the final production deploy.
We’ve been running the project, affectionately named “Drake” [1], for the last couple weeks and have seen some great results. Auto-deploys across all customer sandboxes have been much more consistent with zero dropped push events. Because we decoupled the entrypoint and isolated the error handling, we’ve uncovered a few quirks of API logic that were once hidden in a sea of logs. And finally, due to the exponential backoff scheme employed by our worker server library, we’ve even seen a slight drop in API resource usage.
My main takeaway from the whole process was that even though the big solutions held a lot of appeal, sometimes all one needs is something simple. And I’ll take simple elegance over debt inducing complexity any day of the week.
1: Six-degrees of naming projects at Runnable: Webhook to Hook, to Captain hook, to Pirates, to Sir Francis Drake, and finally to Drake. Its deploy song? You guessed it: Hotline Bling.