A month ago, I wrote about my investigation into an implementation of a real-time socket data manipulator which could eventually stall our application. While trying to research how this stuff actually worked, I couldn’t find many resources explaining how actual code goes through the event loop. Honestly, I think that’s a huge problem. I’m afraid most developers don’t understand the most critical part of Node.js, but I’m here to fix that. So, how do sockets work? How does the socket data get so backed up? Why does using a Transform solve the issue when piping with an async function does not?
Understanding the event loop.
First, let’s have an in-depth look at the phases of the event loop:
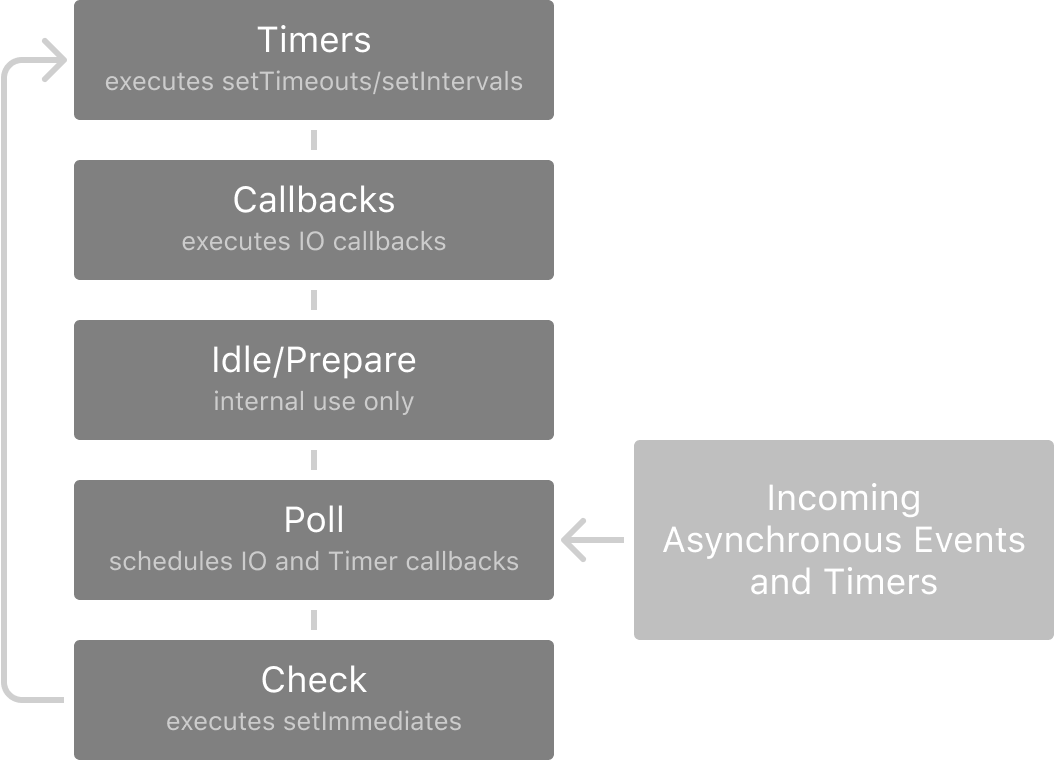
Most of our time is usually spent between the Callbacks and the Poll phases.
The Poll phase is responsible for blocking the current flow of the code to check for incoming asynchronous events or timers. It checks on the response of any of the handlers it’s been given (file handlers, socket handlers) and appends them to the Callbacks phase queue. It also checks to see if any timers have reached zero and appends them to the Timers phase queue.
The Callbacks phase processes all incoming IO callbacks, like network traffic, file streams, and database responses. The Timers phase runs any setTimeout and setInterval callbacks, and the Check phase runs any setImmediate callbacks.
This is the main flow of every Node app. The Poll phase blocks flow waiting for incoming things to do, and when it does, distributes the task to the correct queue, then relinquishes flow so the callbacks may be invoked. Synchronous code that isn’t part of the main execution loop (initial code run) is run in the phase it was called in.
Buffering
Now that we’ve got the basics down, we should talk about how Streams work in Node.JS. Streams are the constructs Node.JS uses to expose the machine’s network Sockets. They use the Node-specific class Buffer to hold their data. Buffers were created as a way to hold large amounts of Binary data, since pre-ES6 didn’t have TypedArray. They are even more special than other structures in Node.js because their memory is allocated outside of the standard V8 heap. This means they have a larger memory allotment than the rest of Node, and they don’t affect the memory pressure of your whole app. Now, that isn’t to say they have unlimited memory; they don’t, but Node.js actually has a few smart tricks to keep everything smooth.
Working with Streams
A Stream is, like the name suggests, a Node construct for a continuous stream of data. When the Stream gets a chunk of data, it adds it to its buffer and fires a data event. Streams won’t let the data flow until there is a data handler added, or it’s specifically told to drain. When data is flowing, When the handler is given to the Poll phase, the Stream will slice as much data as it can from the from the top of its buffer, and give it to the data callback in the Callbacks phase.
Note: The data a Stream splices could be multiple messages or incomplete messages, so be aware of this when processing live data.
How do Streams get backed up?
This is usually referred to as “starving the IO”, but there are quite a few ways this can happen. Synchronous code keeps the event loop on whichever phase triggered the callback (except for the main execution, which isn’t in any phase). This includes event listeners. All listeners to an event are called synchronously, just like a method call. Until the event loop is able to get to the Poll phase, all streams buffer their incoming data in their internal write buffer. If you are streaming continuous data, the buffers can really get backed up the longer the Poll phase is ignored. While the Poll phase is ignored, no new IO can be handled, and your server becomes unresponsive to requests.
Why can’t we use a setTimeout to make a loop asynchronous?
SetTimeout adds a special handler to the Poll queue which triggers after the given amount of time has passed. Why doesn’t this work?
Function getDataWithTimeout (data) {
const length = data.readUInt32BE(4)
const chunk = data.splice(0, length)
process(chunk)
if (data.length) {
setTimeout(getDataWithTimeout, 0, data)
}
}
socket.on(‘data’, getDataWithTimeout)
The Poll phase will check the Stream and trigger the IO callback. Once in there, the data is processed, then the timeout is scheduled. Next Poll phase, there is another IO callback added (brand new data), and the setTimeout is scheduled (since its timeout is 0). Luckily, setTimeout callbacks are done at the beginning of the loop, so we’re still processing stuff in order, which is good!
But here’s the problem: if we have more data at the end of this timeout, the Poll phase will have to schedule the next setTimeout on the next Timer phase. So when the Callbacks phase runs, it will process new data before all the old data is done. Our data just got processed out of order.
Why does a Transform solve the issue?
Transforms were created for transforming data. They are Duplex Streams, which means they have a Read buffer (for something, like a terminal, to read from), and a Write buffer (for something, like TCP Streams, to write to). A Transform gives you a method to transfer data from the Write buffer to the Read buffer, which is exactly what we need. But how is it different? The method’s callback triggers the next chunk of data to the Transform, but until it’s invoked, the data just buffers. This makes sure we never process new data before all of the old data is done. Now our setTimeout works perfectly! It also makes it easier to build incomplete messages until they are complete.
Class Cleanser extends stream.Transform {
constructor(options) { super(options) }
_transform (chunk, enc, cb) {
const length = data.readUInt32BE(4)
const chunk = data.slice(4, length)
this.push(chunk)
data = data.slice(4 + length)
if (data.length) {
setTimeout(transform, 0, data)
} else {
callback()
}
}
}
const cleanser = new Cleanser()
socket.pipe(cleanser)
Conclusion
You could write thousands of lines of code without ever hitting any issues with the event loop. Many people don’t when first writing their apps. But as these apps get more complex by working with different IO, using sockets, and scaling to thousands of users, issues like this can start to pop up.
The Node event loop is not an easy concept to grasp, but understanding how it works can be crucial to writing performant code and avoiding design mistakes that can cause hidden failures. Before you design your new component, understand how it will flow in the event loop, and plan accordingly. You may even be able to use its advanced features to your advantage.