Our problem started out benign enough: we were dealing with third party endpoints that started dropping requests and we could no longer count on to be reliable. The immediate solution was to write retry logic in-place within our API server that instigated these calls, adding a layer of protection around the library that did not have its own retry logic. However, when put under load, this retry logic started becoming a bottleneck, holding onto unnecessary resources and creating race conditions we had never before seen. Debugging it started becoming nightmare-esque and maintaining it became nigh impossible.
Meanwhile, a developer working on a greenfield project was addressing a similar problem. He was interfacing with yet another third party that was mostly reliable but required us to make requests across the internet, increasing the chances for an error to occur. He also had requirements that the tasks must complete eventually and that multiple clients will be providing jobs to be completed. The application would provide some sane defaults and configuration, and require the capability of retrying failed tasks. Having seen the retry logic debacle in the API, it was clear that a new paradigm was necessary.
This developer finally turned to RabbitMQ as a solution. RabbitMQ provides a queuing mechanism for clients to populate with jobs and then distributes the jobs to consumers. He could process one job at a time from RabbitMQ and acknowledge it when it was complete. If the job was failed to be acknowledged in time, RabbitMQ would queue it back to try again, easily providing the retry logic that was required. Thus dawned a new age at Runnable: one of worker servers and queues that help to massively increase reliability and performance in our infrastructure.
The Dawn of Queues
The new age of queues started an inquiry into how to use queues correctly. We discovered quickly how to use single queues to perform tasks, but wanted to be able to send messages to multiple consumers and do more complex message passing. One resource we found to be invaluable was an ebook written about RabbitMQ patterns. Taking the new knowledge of these patterns and the framework from our first task server, a new tool was born we affectionately called “Ponos”.
Ponos is our opinionated worker server that we used to consolidate our ideas about these paradigms. The idea behind it has always been simple: developers write how a job is handled, throw errors when a job is impossible to complete, and simply finish successfully to complete a job.
We implemented two messaging patterns right away. First was the Task Queue, where one queue is used to provide jobs to a worker or distribute jobs among multiple workers. We use this pattern for tasks including sending notifications to GitHub.
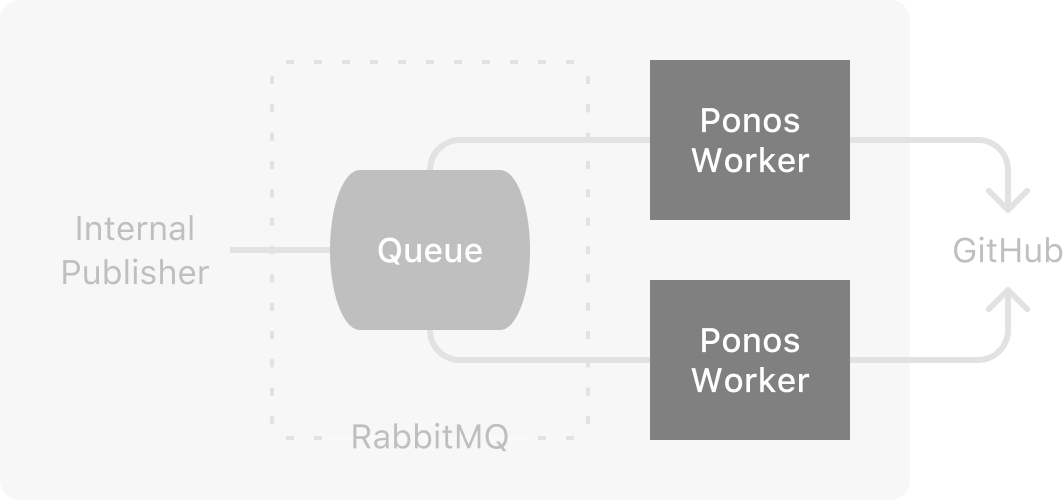
The Task Queue
The second pattern was the Event Queue, a fanout exchange where multiple queues receive jobs from one job being published. We use this pattern when we want multiple parts of our application to execute different tasks in response to a single event. Runnable uses this pattern in multiple capacities managing container lifecycles.
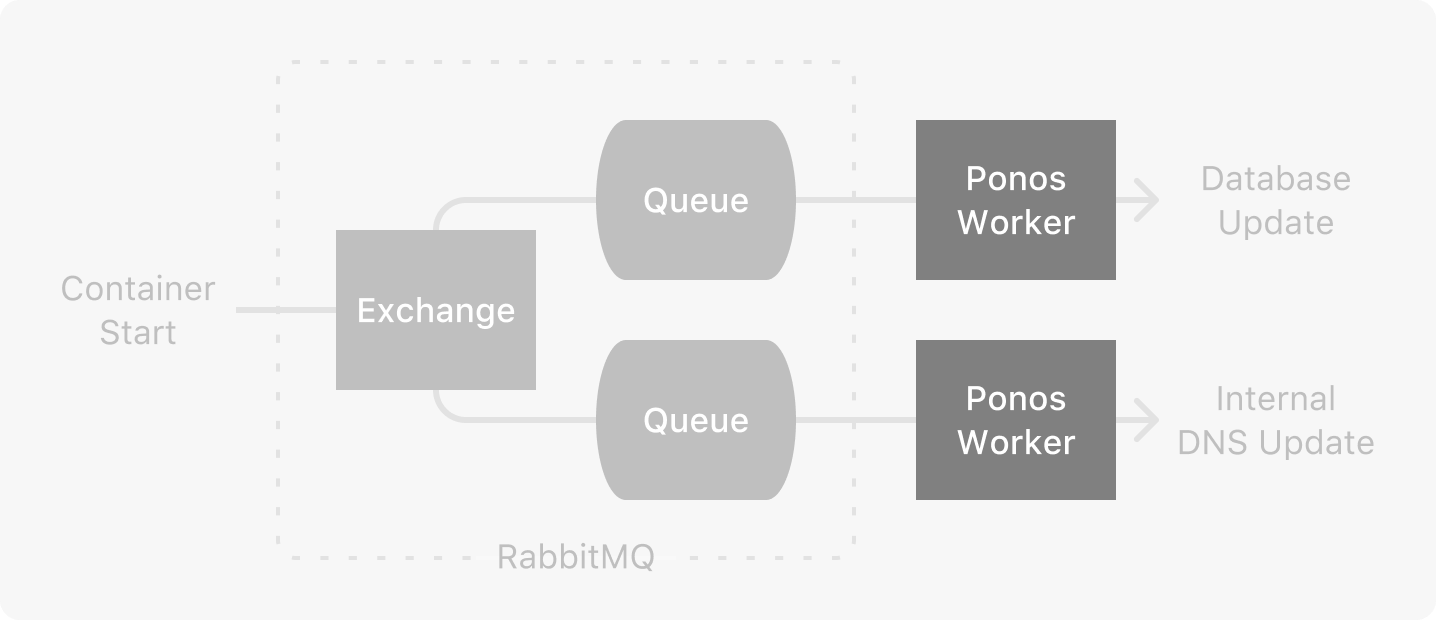
The Event Queue
As Runnable has grown, Ponos has grown with us. Event queues in particular have become more important to our infrastructure as we add more workers that react to single events. We're always considering new patterns to add to Ponos.
Benefits of Ponos
Ponos provides very useful mechanisms around its server and the workers. Logging and error reporting were built into the server and workers to ensure that we always had visibility into what was happening. Because of the nature of working with external services, we implemented exponential backoff and retry logic in our worker: if a request ever fails, an error is thrown which Ponos then catches and retries the task. Once a job enters Ponos, it is required to complete successfully or throw a specific type of error (a WorkerStopError) to indicate that the job cannot be completed, and then the job is acknowledged and removed from the queue. This has given us the amazing ability to make small, easy to maintain (and test!) tasks that are executed in a robust system. Additionally, because RabbitMQ has the ability to maintain queues and messages when a consumer is not present, our worker servers do not lose any of their work as we iterate quickly and deploy them often.
Since creating Ponos, we have integrated it into several projects at Runnable. We use Ponos when interfacing with external and internal services that we know may be slightly unreliable. Ponos has provided us a very clean, sane platform for us to develop.
If you would like to know more about Ponos, you can view the source on GitHub and install it using npm!