We use a number of external services to handle data retrieval, monitoring, and reporting. The importance of each service depends on its role in our sandboxes product. For instance, it’s generally fine if we miss a few reports sent to Datadog but it is not okay if we are unable to reach the GitHub API. In this post, we’ll discuss the issues we’ve faced when interfacing with external services and dive into how we use Varnish Cache to handle them.
Three Problems
We’ve faced three major problems concerning external services during the course of building out the Runnable sandboxes product:
- Latency — the amount of time it takes for the service to handle our requests.
- Availability — whether or not the service can be used and is not experiencing an outage.
- Rate Limiting — whether or not we have hit the maximum number of requests allowed by the provider.
From our perspective, latency is a tough problem since there is often little we can do to address it directly [1]. Similarly we are, for the most part [2], powerless to directly fix service outages. Which leaves us with rate limiting, the only problem we can directly address when designing our software.
Since we’ve moved to a microservice architecture, outbound requests can come from a variety of sources and it can be difficult to directly track and optimize our usage. Furthermore, even if we were able to achieve an optimal minimum, the number of external requests in our system is directly proportional to number of active users. This means as we grow we will make more requests, and eventually we will hit the limits set forth by our external service providers.
There were many ways we could go about solving the rate limiting problem, but the one that seemed most promising (and familiar) was to use a distributed HTTP cache, like Varnish Cache.
Caching Outside of the Box
Varnish is a very fast “caching HTTP reverse proxy” [3] that has seen a lot of success as an in-datacenter frontend for any HTTP based service (APIs, web servers, etc.). In the standard use-case one simply sets a varnish server in front of one or many backend web services, customizes how caching and proxying works via a VCL configuration, then sets memory limits on the LRU cache during the daemon start.

Once running, Varnish will handle all incoming requests on behalf of the application server. When the first request is made to a cacheable resource, it will forward the request to the application server, cache the response, and then send the response back to the end user. Subsequent requests to the same resource will bypass application server entirely and Varnish will simply respond with the cached content. Finally after a manual purge, timeout, or via LRU, the content for the resource will be removed from the cache, and the cycle will begin anew.
By flipping this standard use case around, using the right VCL configuration, and relying on some advanced Varnish features, we can address all three problems discussed in the previous section.
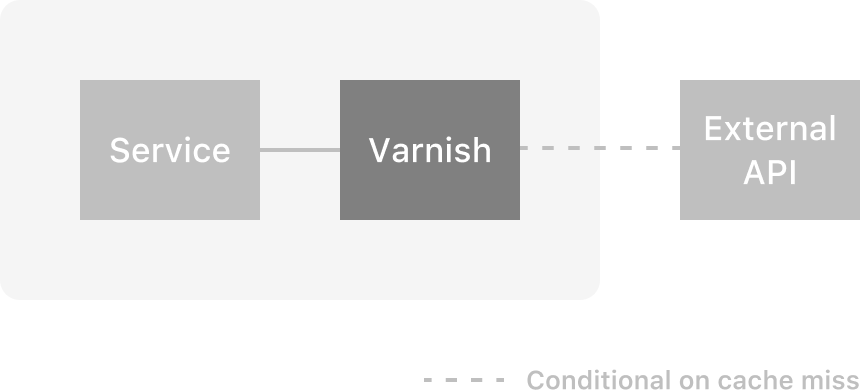
Latency is a problem that can be directly solved by putting varnish between internal services and external APIs [4]. Given that the data remains relatively static (persists longer than a minute or two), one can bypass external requests entirely. This has the effect of dramatically reducing latency when fetching external resources [5].
We can partially address the problem of availability by way of a “grace periods”. Roughly under certain circumstances (such as when it cannot reach backends) one can configure Varnish to serve stale content even if it has been purged or expired from the cache. This means that if the external service is having an outage, you can still get stale “responses” from the service and do as much as you can until things settle down.
Finally, rate limiting is addressed in the exact same way as latency. If you have a decent cache hit ratio in Varnish, then you necessarily make fewer requests to the external service. This means that your service has much more breathing room to work with before hitting any eventual rate limits.
From this perspective it’s pretty clear that Varnish is an excellent tool for the job. But there are still a couple of problems. First, we haven’t actually solved the rate limiting problem, but only made it less pressing by giving ourselves a bit more headroom. Second, Varnish does not handle SSL [6], and nearly all external APIs one might want to leverage require the use of the HTTPS protocol for secure communication.
Putting It All Together: NGINX + Multiple NATs
While Varnish doesn’t handle SSL, there is another HTTP proxy that does: NGINX. To make this work, we setup an Nginx instance that translates incoming HTTP traffic from Varnish to HTTPS traffic outbound to the external service. Then Nginx performs the SSL decryption of the response and sends it back to Varnish via HTTP.
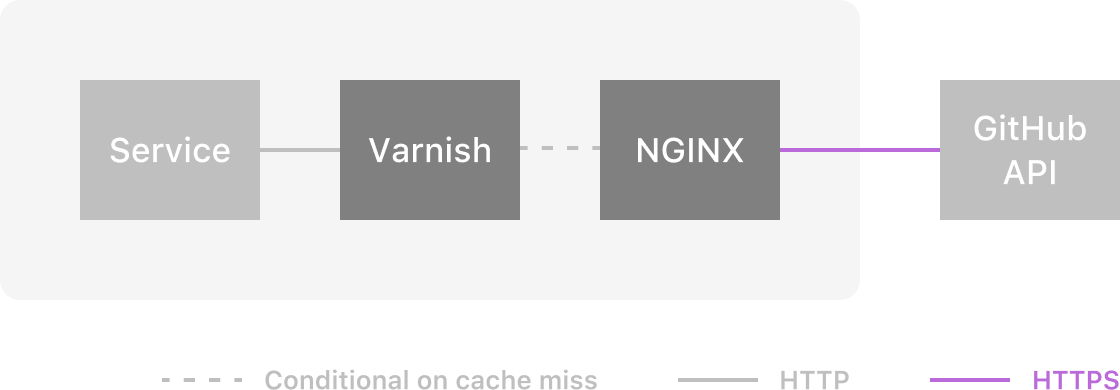
By using the two proxies together, one allows each to do what they do best. Furthermore the solution is actually rather trivial to implement with NGINX [7].
With SSL out of the way, the last problem to fully solve is rate limiting. If you are using a Software Defined Networking solution (e.g. AWS VPC) for your production infrastructure, then one solution is to route outbound traffic through different NATs. In this scheme, one sends high priority requests through one NAT, and low priority requests through another.

For instance, HTTP services could be considered high priority, and worker based services could be considered low priority. HTTP services such as internal or external APIs often do not have retry logic built into routes when external calls fail, but worker servers can be easily coded to use a backoff scheme and retry their task at a later date.
Final Thoughts
While in no way the ultimate solution to handling external services we’re pretty happy with this solution at Runnable. It meets our needs, leverages open source, and is modular enough to easily change in the future. Thanks for reading and happy architecting!
1: Network latency is directly proportional to the distance between our datacenter and the external service’s datacenter. Request processing time depends on the implementation details of the service in question. ↩
2: One way we help is to exponentially backoff requests to failing providers so as to avoid DOSing them when they are already buckling under load. ↩
3: In-depth information on varnish ↩
4: Traditionally one uses it to reduce processing time for HTML rendering (via rails, php, etc.), but companies such as Fastly even use Varnish to help reduce network latency! ↩
5: By default one usually only caches HTTP GET and HEAD requests, as it often does not make sense to cache routes that perform resource mutation. ↩
6: There are some very good reasons as to why this is the case ↩
7: Here’s an example SSL initiation configuration for NGINX ↩